

Hi Guys, off lately I have been reading a memoir written by J.D. Vance and it’s about his own life, how even after so many family and cultural crisis he succeeded in fulfilling his Mammaw(grandmother) and his own dream of pursuing law from Yale University!
So, that’s not my topic of discussion today, it’s related to Natural Language Processing. Now you guys would be wondering then why did I mention about that book. Well, I was reading that book and was parallelly studying about how to represent words in a form of vector and represent them in a 2-dimensional form, which shows us how words are related to each other in semantic and syntactic forms. So, I used this book as my corpus and converted the words into a vector form.
But for now let us dive into NLP, I will not explain to you what it means as it’s just a small piece of work I want to share it with you all, I will rather explain it more profoundly in my blogs that I write on GitHub and WordPress. After reading a paper on “Efficient Estimation of Word Representations in Vector Space” and by going through couple of tutorials on how we can represent words in a form of vector I decided to implement that by following some tutorials, the results were not what I expected out to be so I tweaked with some hyper-parameters in my code and guess what the results improved. I could see similar context words close to each other in a 2 Dimensional space.
I think the main reason for not getting better results at the first time was mainly because my Corpus was pretty small consisting of 79000 tokens and finally after training the model my vocabulary list contained only 2900 words. Initially, I had set a number of features to 300, it’s the dimension per each word vector which means that each word in our corpus will be represented by a 300-dimensional word vector (300 is recommended by the original authors, but that’s based on their empirical observations). But the important point to note here is that all these hyper-parameters reported by the authors are mostly empirical and there isn’t any kind of set heuristics for using them.
So, as I mentioned that my corpus was pretty small, so instead of using a number of features equal to 300, I reduced them though it’s recommended that the more features you have your model is said to take more time to train, more computationally complex but yes it’s more accurate. But guess what in my case the corpus was small so it was better if I would have reduced the vector size and it worked! I used a 250-dimensional vector for each word in my vocabulary list and I used a down-sampling of 1e-3. Let me show you a 250-dimensional vector representation of a word.
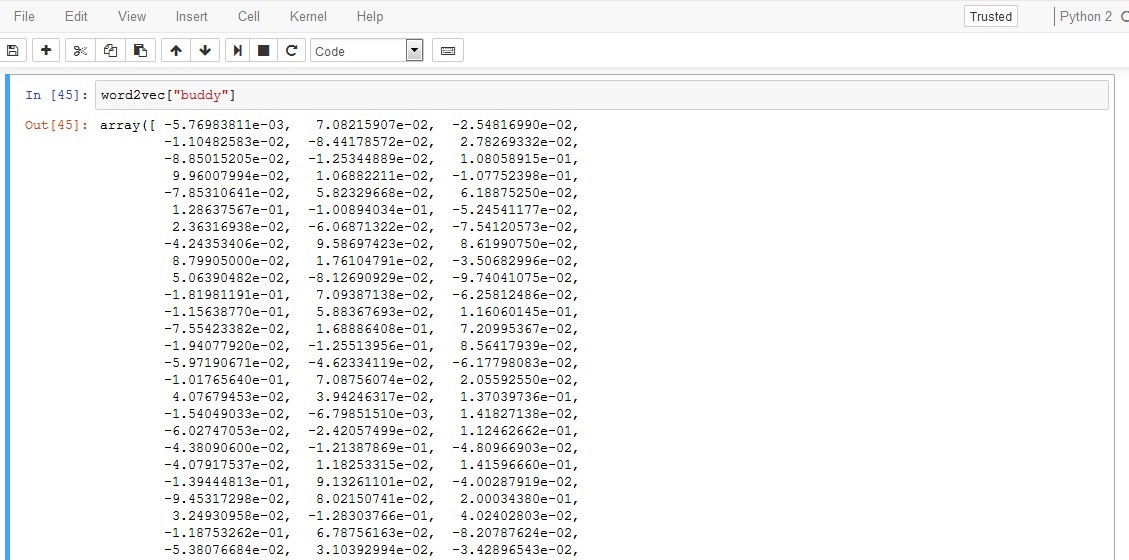
Unfortunately, it’s difficult to show all 250 values of the word, but I think the above image gives you a lot of ideas how a word is represented in a vector form. I further squashed it down to a 2-dimensions consisting of points x and y to represent in a graphical form which can be visualized by humans.
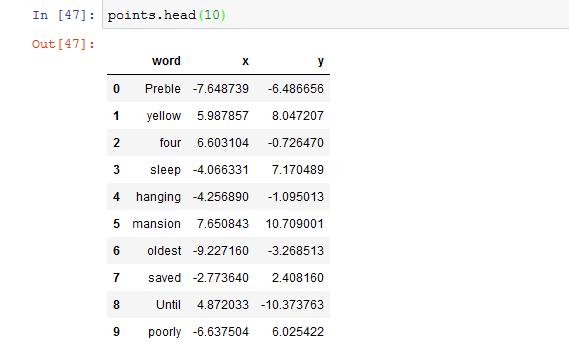
The above image depicts the 10 different words in a vocabulary list and their respective x and y coordinates which we then further plot to visualize their similarity and how close the words are to each other.
Finally, let me show you the graphical representation of the words which will give you a better sense of understanding. Let me also tell you that the similarity might not be 100% accurate as the corpus was small, and this was my first ever experiment on converting words to a vector format. Moreover, I think no one has been able to achieve 100% accuracy till date.
So here we go…
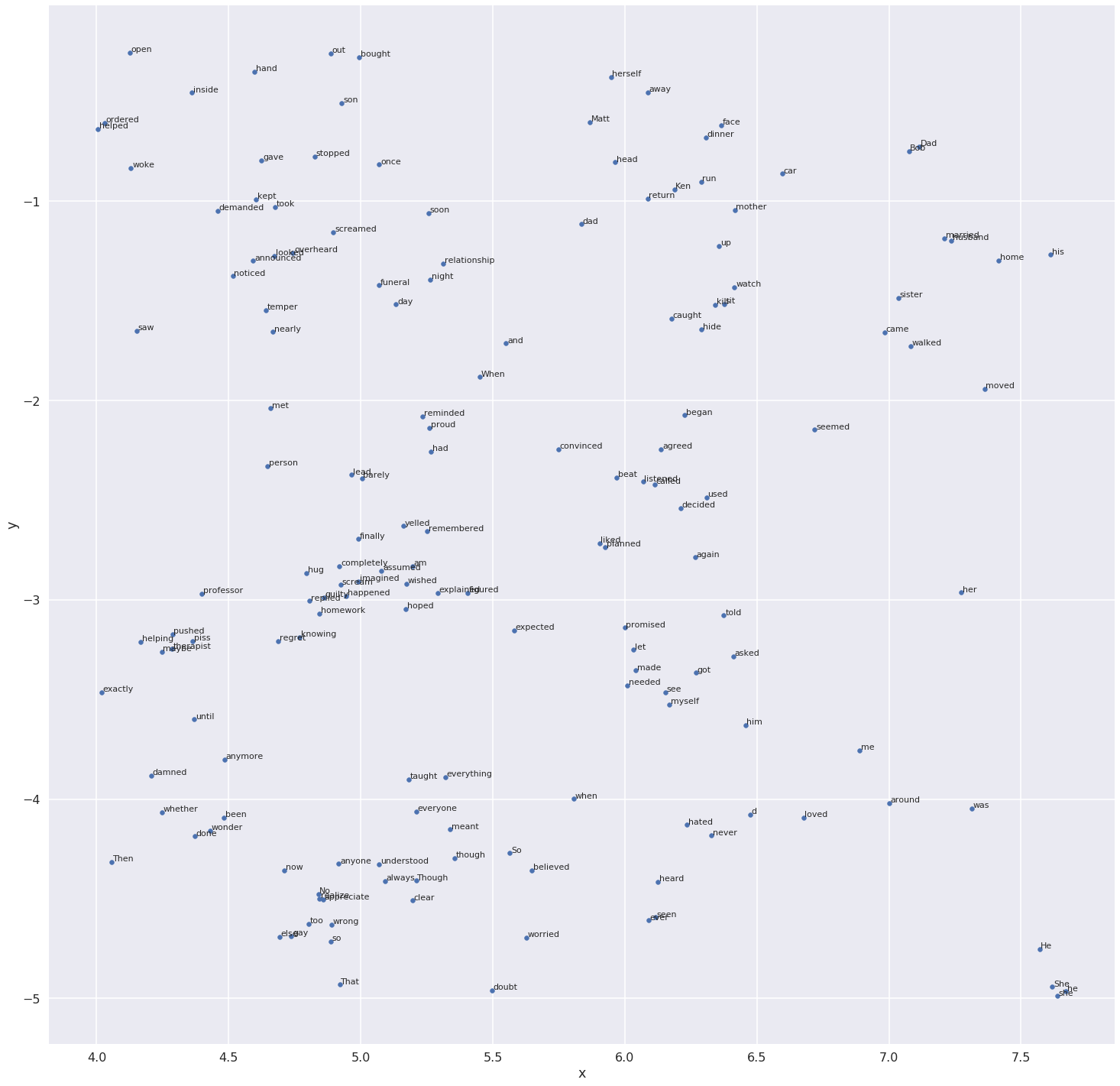
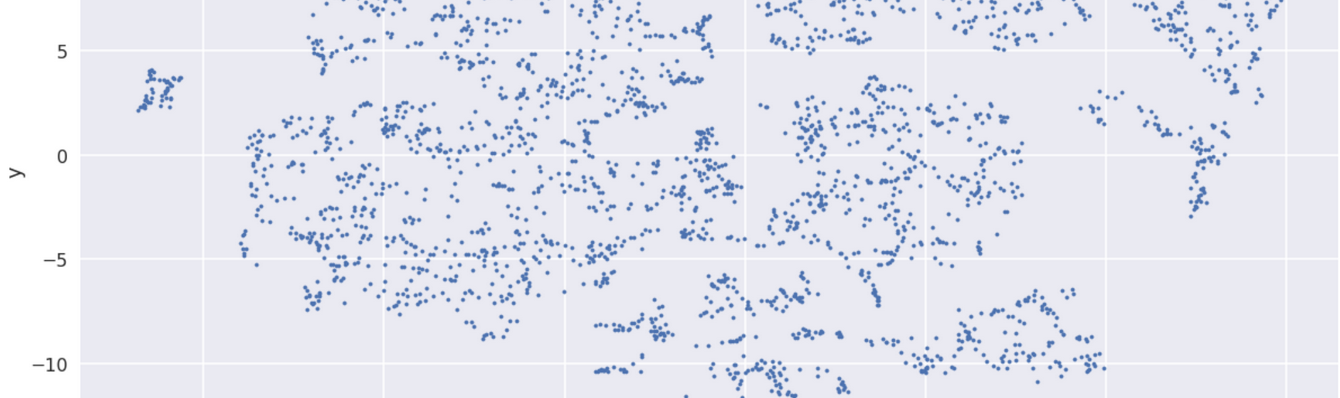
If you zoom in a little you will notice that words like (he, she), (told, asked), (moved, walked, came) etc. are clustered together. This means these words are somewhat similar in context to each other. I have plotted the x coordinate from 4.0 to 8.0 and y coordinates from -5.0 to -0.1 so that means the above plot does not contain all 2900 words. I used TSNE to convert each 250 -dimensional vector into a 2-dimensional space, we can definitely use PCA as well.
Word vectors can be widely used in law, probably train an AI judge, define new drugs using Cosine or Gaussian similarity matrix. We can also use it for ranking research papers like we want to rank papers which have used the word lets say “Climate” maximum number of times.
So, that’s it for this time, hope you all like the article and if it helped you any which way that will motivate me to write more such stuff may be on more profound topics. I will probably write a more technical blog on the same topic on GitHub in some time and will post my code as well.